Chapter 13 Probability
PROBABILITY
13.1 Introduction
In earlier Classes, we have studied the probability as a measure of uncertainty of events in a random experiment. We discussed the axiomatic approach formulated by Russian Mathematician, A.N. Kolmogorov (1903-1987) and treated probability as a function of outcomes of the experiment. We have also established equivalence between the axiomatic theory and the classical theory of probability in case of equally likely outcomes. On the basis of this relationship, we obtained probabilities of events associated with discrete sample spaces. We have also studied the addition rule of probability. In this chapter, we shall discuss the important concept of conditional probability of an event given that another event has occurred, which will be helpful in understanding the Bayes’ theorem, multiplication rule of probability and independence of events. We shall also learn

Pierre de Fermat $(1601-1665)$ an important concept of random variable and its probability distribution and also the mean and variance of a probability distribution. In the last section of the chapter, we shall study an important discrete probability distribution called Binomial distribution. Throughout this chapter, we shall take up the experiments having equally likely outcomes, unless stated otherwise.
13.2 Conditional Probability
Uptill now in probability, we have discussed the methods of finding the probability of events. If we have two events from the same sample space, does the information about the occurrence of one of the events affect the probability of the other event? Let us try to answer this question by taking up a random experiment in which the outcomes are equally likely to occur.
Consider the experiment of tossing three fair coins. The sample space of the experiment is
$ S={HHH, HHT, HTH, THH, HTT, THT, TTH, TTT} $
Since the coins are fair, we can assign the probability $\frac{1}{8}$ to each sample point. Let $E$ be the event ‘at least two heads appear’ and $F$ be the event ‘first coin shows tail’. Then

Now, suppose we are given that the first coin shows tail, i.e. F occurs, then what is the probability of occurrence of $E$ ? With the information of occurrence of $F$, we are sure that the cases in which first coin does not result into a tail should not be considered while finding the probability of $E$. This information reduces our sample space from the set $S$ to its subset $F$ for the event $E$. In other words, the additional information really amounts to telling us that the situation may be considered as being that of a new random experiment for which the sample space consists of all those outcomes only which are favourable to the occurrence of the event $F$.
Now, the sample point of $F$ which is favourable to event $E$ is THH.
Thus, Probability of $E$ considering $F$ as the sample space $=\frac{1}{4}$,
or $\quad$ Probability of $E$ given that the event $F$ has occurred $=\frac{1}{4}$
This probability of the event $E$ is called the conditional probability of $E$ given that $F$ has already occurred, and is denoted by $P(E \mid F)$.
Thus $\quad P(E \mid F)=\frac{1}{4}$
Note that the elements of $F$ which favour the event $E$ are the common elements of $E$ and $F$, i.e. the sample points of $E \cap F$.
Thus, we can also write the conditional probability of $E$ given that $F$ has occurred as
$ \begin{aligned} P(E \mid F) & =\frac{\text{ Number of elementary events favourable to } E \cap F}{\text{ Number of elementary events which are favourable to } F} \\ & =\frac{n(E \cap F)}{n(F)} \end{aligned} $
Dividing the numerator and the denominator by total number of elementary events of the sample space, we see that $P(EIF)$ can also be written as
$ P(E \mid F)=\frac{\frac{n(E \cap F)}{n(S)}}{\frac{n(F)}{n(S)}}=\frac{P(E \cap F)}{P(F)} $
Note that (1) is valid only when $P(F) \neq 0$ i.e., $F \neq \phi$ (Why?)
Thus, we can define the conditional probability as follows :
Definition 1
If $E$ and $F$ are two events associated with the same sample space of a random experiment, the conditional probability of the event $E$ given that $F$ has occurred, i.e. $P(E \mid F)$ is given by
$ P(EIF)=\frac{P(E \cap F)}{P(F)} \text{ provided } P(F) \neq 0 $
13.2.1 Properties of conditional probability
Let $E$ and $F$ be events of a sample space $S$ of an experiment, then we have Property $1 P(S \mid F)=P(F \mid F)=1$
We know that
Also
$ \begin{aligned} & P(S \mid F)=\frac{P(S \cap F)}{P(F)}=\frac{P(F)}{P(F)}=1 \\ & P(F \mid F)=\frac{P(F \cap F)}{P(F)}=\frac{P(F)}{P(F)}=1 \\ & P(S \mid F)=P(F \mid F)=1 \end{aligned} $
Thus
Property 2 If $A$ and $B$ are any two events of a sample space $S$ and $F$ is an event of $S$ such that $P(F) \neq 0$, then
$ P((A \cup B) \mid F)=P(A \mid F)+P(B \mid F)-P((A \cap B) \mid F) $
In particular, if $A$ and $B$ are disjoint events, then
We have
$ P((A \cup B) \mid F)=P(A \mid F)+P(B \mid F) $
$ \begin{aligned} P((A \cup B) \mid F) & =\frac{P[(A \cup B) \cap F]}{P(F)} \\ & =\frac{P[(A \cap F) \cup(B \cap F)]}{P(F)} \end{aligned} $
(by distributive law of union of sets over intersection)
$ \begin{aligned} & =\frac{P(A \cap F)+P(B \cap F)-P(A \cap B \cap F)}{P(F)} \\ & =\frac{P(A \cap F)}{P(F)}+\frac{P(B \cap F)}{P(F)}-\frac{P[(A \cap B) \cap F]}{P(F)} \\ & =P(A \mid F)+P(B \mid F)-P((A \cap B) \mid F) \end{aligned} $
When $A$ and $B$ are disjoint events, then
$
\begin{matrix}
& P((A \cap B) \mid F)=0 \\
\Rightarrow \quad & P((A \cup B) \mid F)=P(A \mid F)+P(B \mid F)
\end{matrix}
$
Property $3 P(E^{\prime} \mid F)=1-P(E \mid F)$
From Property 1 , we know that $P(SIF)=1$
$ \begin{matrix} \Rightarrow & P(E \cup E^{\prime} \mid F)=1 & \text{ since } S=E \cup E^{\prime} \\ \Rightarrow & P(E \mid F)+P(E^{\prime} \mid F)=1 & \text{ since } E \text{ and } E^{\prime} \text{ are disjoint events } \\ \text{ Thus, } & P(E^{\prime} \mid F)=1-P(E \mid F) & \end{matrix} $
Let us now take up some examples.
13.3 Multiplication Theorem on Probability
Let $E$ and $F$ be two events associated with a sample space $S$. Clearly, the set $E \cap F$ denotes the event that both $E$ and $F$ have occurred. In other words, $E \cap F$ denotes the simultaneous occurrence of the events $E$ and $F$. The event $E \cap F$ is also written as $EF$.
Very often we need to find the probability of the event EF. For example, in the experiment of drawing two cards one after the other, we may be interested in finding the probability of the event ‘a king and a queen’. The probability of event EF is obtained by using the conditional probability as obtained below :
We know that the conditional probability of event $E$ given that $F$ has occurred is denoted by $P(E \mid F)$ and is given by
$ P(E \mid F)=\frac{P(E \cap F)}{P(F)}, P(F) \neq 0 $
From this result, we can write
$ P(E \cap F)=P(F) . P(E \mid F) $
Also, we know that
or
$ \begin{aligned} & P(F \mid E)=\frac{P(F \cap E)}{P(E)}, P(E) \neq 0 \\ & P(F \mid E)=\frac{P(E \cap F)}{P(E)}(\text{ since } E \cap F=F \cap E) \end{aligned} $
Thus,
$ P(E \cap F)=P(E) . P(F \mid E) $
Combining (1) and (2), we find that
$ \begin{aligned} P(E \cap F) & =P(E) P(F \mid E) \\ & =P(F) P(E \mid F) \text{ provided } P(E) \neq 0 \text{ and } P(F) \neq 0 . \end{aligned} $
The above result is known as the multiplication rule of probability.
Let us now take up an example.
13.4 Independent Events
Consider the experiment of drawing a card from a deck of 52 playing cards, in which the elementary events are assumed to be equally likely. If $E$ and $F$ denote the events ’the card drawn is a spade’ and ’the card drawn is an ace’ respectively, then
$ P(E)=\frac{13}{52}=\frac{1}{4} \text{ and } P(F)=\frac{4}{52}=\frac{1}{13} $
Also $E$ and $F$ is the event ’ the card drawn is the ace of spades’ so that
Hence
$ \begin{aligned} & P(E \cap F)=\frac{1}{52} \\ & P(E \mid F)=\frac{P(E \cap F)}{P(F)}=\frac{\frac{1}{52}}{\frac{1}{13}}=\frac{1}{4} \end{aligned} $
Since $P(E)=\frac{1}{4}=P(E \mid F)$, we can say that the occurrence of event $F$ has not affected the probability of occurrence of the event $E$.
We also have
$ P(F \mid E)=\frac{P(E \cap F)}{P(E)}=\frac{\frac{1}{52}}{\frac{1}{4}}=\frac{1}{13}=P(F) $
Again, $P(F)=\frac{1}{13}=P(F \mid E)$ shows that occurrence of event $E$ has not affected the probability of occurrence of the event $F$.
Thus, $E$ and $F$ are two events such that the probability of occurrence of one of them is not affected by occurrence of the other.
Such events are called independent events.
Definition 2 Two events $E$ and $F$ are said to be independent, if
$ \begin{aligned} & P(F \mid E)=P(F) \text{ provided } P(E) \neq 0 \\ & P(E \mid F)=P(E) \text{ provided } P(F) \neq 0 \end{aligned} $
and
Thus, in this definition we need to have $P(E) \neq 0$ and $P(F) \neq 0$
Now, by the multiplication rule of probability, we have
$ P(E \cap F)=P(E) \cdot P(F \mid E) $
If $E$ and $F$ are independent, then (1) becomes
$ P(E \cap F)=P(E) \cdot P(F) $
Thus, using (2), the independence of two events is also defined as follows:
Definition 3 Let $E$ and $F$ be two events associated with the same random experiment, then $E$ and $F$ are said to be independent if
$ P(E \cap F)=P(E) . P(F) $
Remarks
(i) Two events $E$ and $F$ are said to be dependent if they are not independent, i.e. if
$ P(E \cap F) \neq P(E) . P(F) $
(ii) Sometimes there is a confusion between independent events and mutually exclusive events. Term ‘independent’ is defined in terms of ‘probability of events’ whereas mutually exclusive is defined in term of events (subset of sample space). Moreover, mutually exclusive events never have an outcome common, but independent events, may have common outcome. Clearly, ‘independent’ and ‘mutually exclusive’ do not have the same meaning.
In other words, two independent events having nonzero probabilities of occurrence can not be mutually exclusive, and conversely, i.e. two mutually exclusive events having nonzero probabilities of occurrence can not be independent.
(iii) Two experiments are said to be independent if for every pair of events $E$ and $F$, where $E$ is associated with the first experiment and $F$ with the second experiment, the probability of the simultaneous occurrence of the events $E$ and $F$ when the two experiments are performed is the product of $P(E)$ and $P(F)$ calculated separately on the basis of two experiments, i.e., $P(E \cap F)=P(E)$. $P(F)$
(iv) Three events A, B and C are said to be mutually independent, if
$ \begin{aligned} P(A \cap B) & =P(A) P(B) \\ P(A \cap C) & =P(A) P(C) \\ P(B \cap C) & =P(B) P(C) \end{aligned} $
$ \text{ and } \quad P(A \cap B \cap C)=P(A) P(B) P(C) $
If at least one of the above is not true for three given events, we say that the events are not independent.
13.5 Bayes’ Theorem
Consider that there are two bags I and II. Bag I contains 2 white and 3 red balls and Bag II contains 4 white and 5 red balls. One ball is drawn at random from one of the bags. We can find the probability of selecting any of the bags (i.e. $\frac{1}{2}$ ) or probability of drawing a ball of a particular colour (say white) from a particular bag (say Bag I). In other words, we can find the probability that the ball drawn is of a particular colour, if we are given the bag from which the ball is drawn. But, can we find the probability that the ball drawn is from a particular bag (say Bag II), if the colour of the ball drawn is given? Here, we have to find the reverse probability of Bag II to be selected when an event occurred after it is known. Famous mathematician, John Bayes’ solved the problem of finding reverse probability by using conditional probability. The formula developed by him is known as ‘Bayes theorem’ which was published posthumously in 1763. Before stating and proving the Bayes’ theorem, let us first take up a definition and some preliminary results.
13.5.1 Partition of a sample space
A set of events $E_1, E_2, \ldots, E_n$ is said to represent a partition of the sample space $S$ if
(a) $E_i \cap E_j=\phi, i \neq j, i, j=1,2,3, \ldots, n$ (b) $E_1 \cup E_2 \cup \ldots \cup E_n=S$ and
(c) $P(E_i)>0$ for all $i=1,2, \ldots, n$.
In other words, the events $E_1, E_2, \ldots, E_n$ represent a partition of the sample space $S$ if they are pairwise disjoint, exhaustive and have nonzero probabilities.
As an example, we see that any nonempty event $E$ and its complement $E^{\prime}$ form a partition of the sample space $S$ since they satisfy $E \cap E^{\prime}=\phi$ and $E \cup E^{\prime}=S$.
From the Venn diagram in Fig 13.3, one can easily observe that if $E$ and $F$ are any two events associated with a sample space $S$, then the set ${E \cap F^{\prime}, E \cap F, E^{\prime} \cap F, E^{\prime} \cap F^{\prime}}$ is a partition of the sample space $S$. It may be mentioned that the partition of a sample space is not unique. There can be several partitions of the same sample space.
We shall now prove a theorem known as Theorem of total probability.
13.5.2 Theorem of total probability
Let ${E_1, E_2, \ldots, E_n}$ be a partition of the sample space $S$, and suppose that each of the events $E_1, E_2, \ldots, E_n$ has nonzero probability of occurrence. Let $A$ be any event associated with $S$, then
$ \begin{aligned} P(A) & =P(E_1) P(AlE_1)+P(E_2) P(AlE_2)+\ldots+P(E_n) P(AlE_n) \\ & =\sum _{j=1}^{n} P(E_j) P(AlE_j) \end{aligned} $
Proof Given that $E_1, E_2, \ldots, E_n$ is a partition of the sample space $S$ (Fig 13.4). Therefore,
$ S=E_1 \cup E_2 \cup \ldots \cup E_n $
and
$ E_i \cap E_j=\phi, i \neq j, i, j=1,2, \ldots, n $
Now, we know that for any event $A$,
$ \begin{aligned} A & =A \cap S \\ & =A \cap(E_1 \cup E_2 \cup \ldots \cup E_n) \\ & =(A \cap E_1) \cup(A \cap E_2) \cup \ldots \cup(A \cap E_n) \end{aligned} $
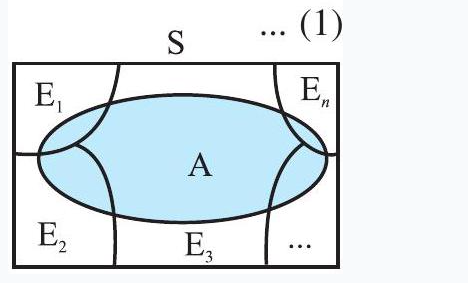
Fig 13.4
Also $A \cap E_i$ and $A \cap E_j$ are respectively the subsets of $E_i$ and $E_j$. We know that $E_i$ and $E_j$ are disjoint, for $i \neq j$, therefore, $A \cap E_i$ and $A \cap E_j$ are also disjoint for all $i \neq j, i, j=1,2, \ldots, n$.
Thus,
$ \begin{aligned} P(A) & =P[(A \cap E_1) \cup(A \cap E_2) \cup \ldots . . \cup(A \cap E_n)] \\ & =P(A \cap E_1)+P(A \cap E_2)+\ldots+P(A \cap E_n) \end{aligned} $
Now, by multiplication rule of probability, we have
$ P(A \cap E_i)=P(E_i) P(AlE_i) \text{ as } P(E_i) \neq 0 \forall i=1,2, \ldots, n $
Therefore,
$ P(A)=P(E_1) P(AlE_1)+P(E_2) P(AlE_2)+\ldots+P(E_n) P(AlE_n) $
or
$ P(A)=\sum _{j=1}^{n} P(E_j) P(AlE_j) $
Remark The following terminology is generally used when Bayes’ theorem is applied.
The events $E_1, E_2, \ldots, E_n$ are called hypotheses.
The probability $P(E_i)$ is called the priori probability of the hypothesis $E_i$
The conditional probability $P(E_i \mid A)$ is called a posteriori probability of the hypothesis $E_i$.
Bayes’ theorem is also called the formula for the probability of “causes”. Since the $E_i$ ’s are a partition of the sample space $S$, one and only one of the events $E_i$ occurs (i.e. one of the events $E_i$ must occur and only one can occur). Hence, the above formula gives us the probability of a particular $E_i$ (i.e. a “Cause”), given that the event $A$ has occurred.
The Bayes’ theorem has its applications in variety of situations, few of which are illustrated in following examples.
Remark A random variable is a real valued function whose domain is the sample space of a random experiment.
For example, let us consider the experiment of tossing a coin two times in succession.
The sample space of the experiment is $S={HH, HT, TH, TT}$.
If $X$ denotes the number of heads obtained, then $X$ is a random variable and for each outcome, its value is as given below :
$ X(HH)=2, X(HT)=1, X(TH)=1, X(TT)=0 . $
More than one random variables can be defined on the same sample space. For example, let $Y$ denote the number of heads minus the number of tails for each outcome of the above sample space $S$.
Then
$ Y(HH)=2, Y(HT)=0, Y(TH)=0, Y(TT)=-2 $
Thus, $X$ and $Y$ are two different random variables defined on the same sample space $S$.
Summary
The salient features of the chapter are -
The conditional probability of an event $E$, given the occurrence of the event $F$ is given by $P(E \mid F)=\frac{P(E \cap F)}{P(F)}, P(F) \neq 0$
$\Delta 0 \leq P(E \mid F) \leq 1, \quad P(E^{\prime} \mid F)=1-P(E \mid F)$
$P((E \cup F) \mid G)=P(E \mid G)+P(F \mid G)-P((E \cap F) \mid G)$
$\Delta P(E \cap F)=P(E) P(F \mid E), P(E) \neq 0$
$P(E \cap F)=P(F) P(EIF), P(F) \neq 0$
$\checkmark$ If $E$ and $F$ are independent, then
$P(E \cap F)=P(E) P(F)$
$P(EIF)=P(E), P(F) \neq 0$
$P(F \mid E)=P(F), P(E) \neq 0$
- Theorem of total probability
Let ${E_1, E_2, \ldots, E_n)$ be a partition of a sample space and suppose that each of $E_1, E_2, \ldots, E_n$ has nonzero probability. Let $A$ be any event associated with $S$, then
$P(A)=P(E_1) P(AlE_1)+P(E_2) P(AlE_2)+\ldots+P(E_n) P(AlE_n)$
Bayes’ theorem If $E_1, E_2, \ldots, E_n$ are events which constitute a partition of sample space $S$, i.e. $E_1, E_2, \ldots, E_n$ are pairwise disjoint and $E_1 \cup E_2 \cup \ldots \cup E_n=S$ and $A$ be any event with nonzero probability, then
$ P(E_i \mid A)=\frac{P(E_i) P(A \mid E_i)}{\sum _{j=1}^{n} P(E_j) P(A \mid E_j)} $
Historical Note
The earliest indication on measurement of chances in game of dice appeared in 1477 in a commentary on Dante’s Divine Comedy. A treatise on gambling named liber de Ludo Alcae, by Geronimo Carden (1501-1576) was published posthumously in 1663 . In this treatise, he gives the number of favourable cases for each event when two dice are thrown.
Galileo (1564-1642) gave casual remarks concerning the correct evaluation of chance in a game of three dice. Galileo analysed that when three dice are thrown, the sum of the number that appear is more likely to be 10 than the sum 9 , because the number of cases favourable to 10 are more than the number of cases for the appearance of number 9.
Apart from these early contributions, it is generally acknowledged that the true origin of the science of probability lies in the correspondence between two great men of the seventeenth century, Pascal (1623-1662) and Pierre de Fermat (1601-1665). A French gambler, Chevalier de Metre asked Pascal to explain some seeming contradiction between his theoretical reasoning and the observation gathered from gambling. In a series of letters written around 1654, Pascal and Fermat laid the first foundation of science of probability. Pascal solved the problem in algebraic manner while Fermat used the method of combinations.
Great Dutch Scientist, Huygens (1629-1695), became acquainted with the content of the correspondence between Pascal and Fermat and published a first book on probability, “De Ratiociniis in Ludo Aleae” containing solution of many interesting rather than difficult problems on probability in games of chances.
The next great work on probability theory is by Jacob Bernoulli (1654-1705), in the form of a great book, “Ars Conjectendi” published posthumously in 1713 by his nephew, Nicholes Bernoulli. To him is due the discovery of one of the most important probability distribution known as Binomial distribution. The next remarkable work on probability lies in 1993. A. N. Kolmogorov (1903-1987) is credited with the axiomatic theory of probability. His book, ‘Foundations of probability’ published in 1933, introduces probability as a set function and is considered a ‘classic!’.





