Chapter 12 Statistics
12.1 Graphical Representation of Data
The representation of data by tables has already been discussed. Now let us turn our attention to another representation of data, i.e., the graphical representation. It is well said that one picture is better than a thousand words. Usually comparisons among the individual items are best shown by means of graphs. The representation then becomes easier to understand than the actual data. We shall study the following graphical representations in this section.
(A) Bar graphs
(B) Histograms of uniform width, and of varying widths
(C) Frequency polygons
(A) Bar Graphs
In earlier classes, you have already studied and constructed bar graphs. Here we shall discuss them through a more formal approach. Recall that a bar graph is a pictorial representation of data in which usually bars of uniform width are drawn with equal spacing between them on one axis (say, the
Example 1 : In a particular section of Class IX, 40 students were asked about the months of their birth and the following graph was prepared for the data so obtained:
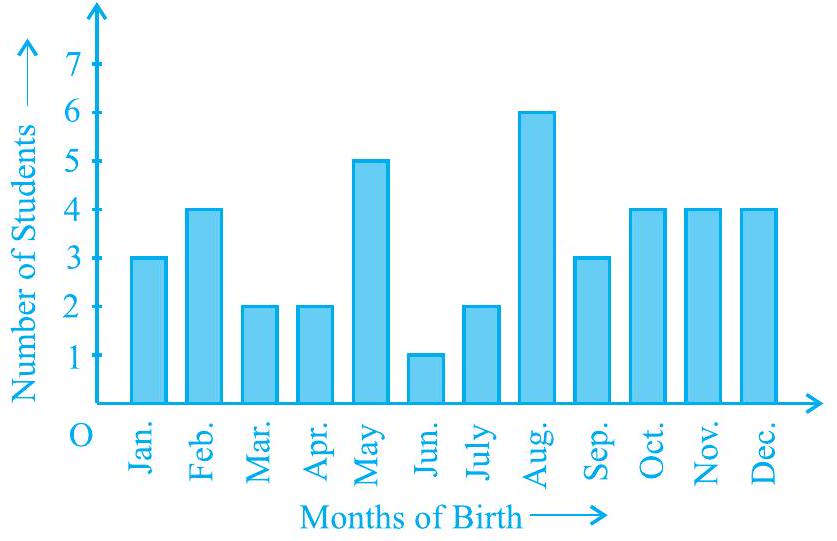
Fig. 12.1
Observe the bar graph given above and answer the following questions:
(i) How many students were born in the month of November?
(ii) In which month were the maximum number of students born?
Solution : Note that the variable here is the ‘month of birth’, and the value of the variable is the ‘Number of students born’.
(i) 4 students were born in the month of November.
(ii) The Maximum number of students were born in the month of August.
Let us now recall how a bar graph is constructed by considering the following example.
Example 2 : A family with a monthly income of ₹ 20,000 had planned the following expenditures per month under various heads:
Table 12.1
| Heads | Expenditure (in thousand rupees) |
|---|---|
| Grocery | 4 |
| Rent | 5 |
| Education of children | 5 |
| Medicine | 2 |
| Fuel | 2 |
| Entertainment | 1 |
| Miscellaneous | 1 |
Draw a bar graph for the data above.
Solution : We draw the bar graph of this data in the following steps. Note that the unit in the second column is thousand rupees. So, ‘4’ against ‘grocery’ means ₹4000.
1. We represent the Heads (variable) on the horizontal axis choosing any scale, since the width of the bar is not important. But for clarity, we take equal widths for all bars and maintain equal gaps in between. Let one Head be represented by one unit.
2. We represent the expenditure (value) on the vertical axis. Since the maximum expenditure is ₹ 5000 , we can choose the scale as 1 unit =₹ 1000.
3. To represent our first Head, i.e., grocery, we draw a rectangular bar with width 1 unit and height 4 units.
4. Similarly, other Heads are represented leaving a gap of 1 unit in between two consecutive bars.
The bar graph is drawn in Fig. 12.2.
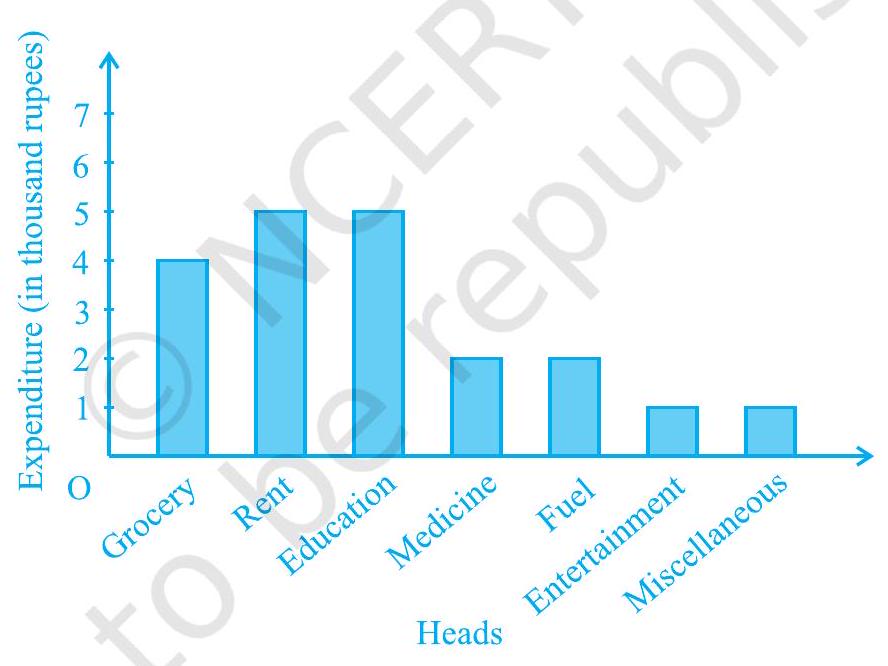
Fig. 12.2
Here, you can easily visualise the relative characteristics of the data at a glance, e.g., the expenditure on education is more than double that of medical expenses. Therefore, in some ways it serves as a better representation of data than the tabular form.
Activity 1 : Continuing with the same four groups of Activity 1, represent the data by suitable bar graphs.
Let us now see how a frequency distribution table for continuous class intervals can be represented graphically.
(B) Histogram
This is a form of representation like the bar graph, but it is used for continuous class intervals. For instance, consider the frequency distribution Table 12.2, representing the weights of 36 students of a class:
Table 12.2
| Weights (in kg) | Number of students |
|---|---|
| 9 | |
| 6 | |
| 15 | |
| 3 | |
| 1 | |
| 2 | |
| Total | 36 |
Let us represent the data given above graphically as follows:
(i) We represent the weights on the horizontal axis on a suitable scale. We can choose the scale as
(ii) We represent the number of students (frequency) on the vertical axis on a suitable scale. Since the maximum frequency is 15 , we need to choose the scale to accomodate this maximum frequency.
(iii) We now draw rectangles (or rectangular bars) of width equal to the class-size and lengths according to the frequencies of the corresponding class intervals. For example, the rectangle for the class interval
(iv) In this way, we obtain the graph as shown in Fig. 12.3:
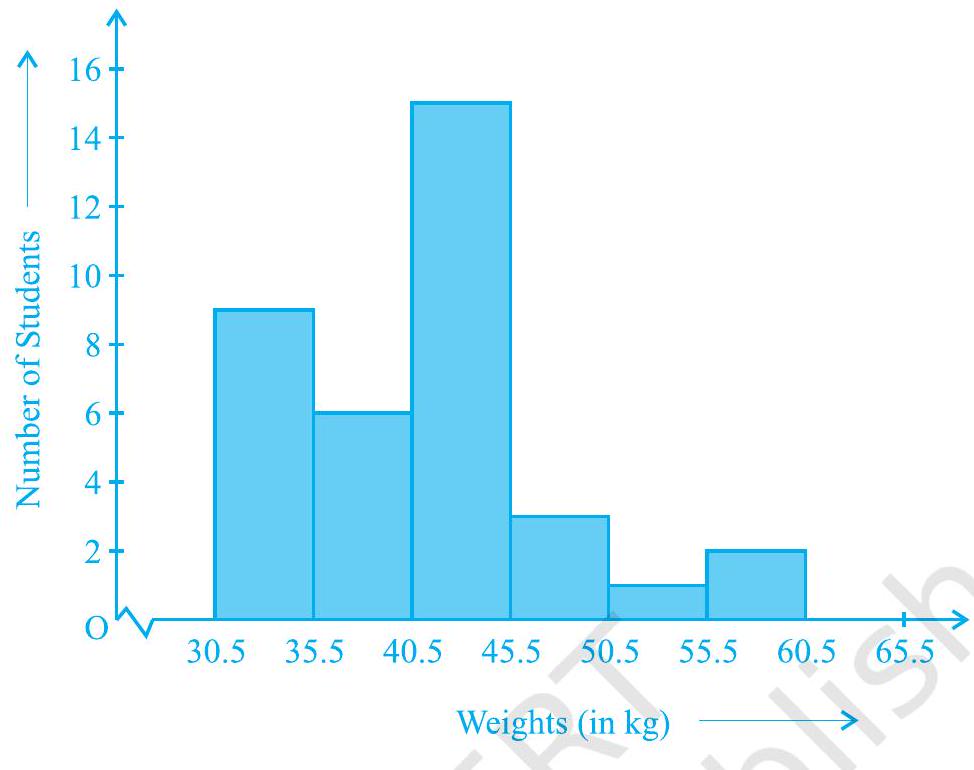
Fig. 12.3
Observe that since there are no gaps in between consecutive rectangles, the resultant graph appears like a solid figure. This is called a histogram, which is a graphical representation of a grouped frequency distribution with continuous classes. Also, unlike a bar graph, the width of the bar plays a significant role in its construction.
Here, in fact, areas of the rectangles erected are proportional to the corresponding frequencies. However, since the widths of the rectangles are all equal, the lengths of the rectangles are proportional to the frequencies. That is why, we draw the lengths according to (iii) above.
Now, consider a situation different from the one above.
Example 3 : A teacher wanted to analyse the performance of two sections of students in a mathematics test of 100 marks. Looking at their performances, she found that a few students got under 20 marks and a few got 70 marks or above. So she decided to group them into intervals of varying sizes as follows:
Table 12.3
| Marks | Number of students |
|---|---|
| 7 | |
| 10 | |
| 10 | |
| 20 | |
| 20 | |
| 15 | |
| 8 | |
| Total | 90 |
A histogram for this table was prepared by a student as shown in Fig. 12.4.
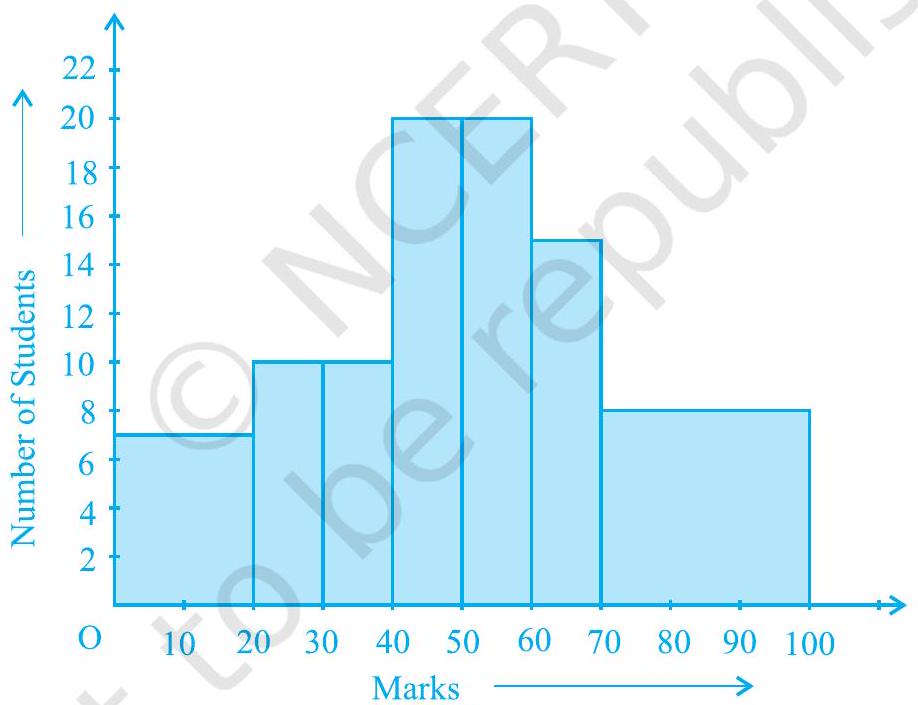
Fig. 12.4
Carefully examine this graphical representation. Do you think that it correctly represents the data? No, the graph is giving us a misleading picture. As we have mentioned earlier, the areas of the rectangles are proportional to the frequencies in a histogram. Earlier this problem did not arise, because the widths of all the rectangles were equal. But here, since the widths of the rectangles are varying, the histogram above does not
give a correct picture. For example, it shows a greater frequency in the interval
So, we need to make certain modifications in the lengths of the rectangles so that the areas are again proportional to the frequencies.
The steps to be followed are as given below:
- Select a class interval with the minimum class size. In the example above, the minimum class-size is 10 .
- The lengths of the rectangles are then modified to be proportionate to the class-size 10.
For instance, when the class-size is 20 , the length of the rectangle is 7 . So when the class-size is 10 , the length of the rectangle will be
Similarly, proceeding in this manner, we get the following table:
Table 12.4
| Marks | Frequency | Width of the class |
Length of the rectangle |
|---|---|---|---|
| 7 | 20 | ||
| 10 | 10 | ||
| 10 | 10 | ||
| 20 | 10 | ||
| 20 | 10 | ||
| 15 | 10 | ||
| 8 | 30 |
Since we have calculated these lengths for an interval of 10 marks in each case, we may call these lengths as “proportion of students per 10 marks interval”.
So, the correct histogram with varying width is given in Fig. 12.5.

Fig. 12.5
(C) Frequency Polygon
There is yet another visual way of representing quantitative data and its frequencies. This is a polygon. To see what we mean, consider the histogram represented by Fig. 12.3. Let us join the mid-points of the upper sides of the adjacent rectangles of this histogram by means of line segments. Let us call these mid-points B, C, D, E, F and G. When joined by line segments, we obtain the figure BCDEFG (see Fig. 12.6). To complete the polygon, we assume that there is a class interval with frequency zero
before 30.5 - 35.5, and one after 55.5 - 60.5, and their mid-points are
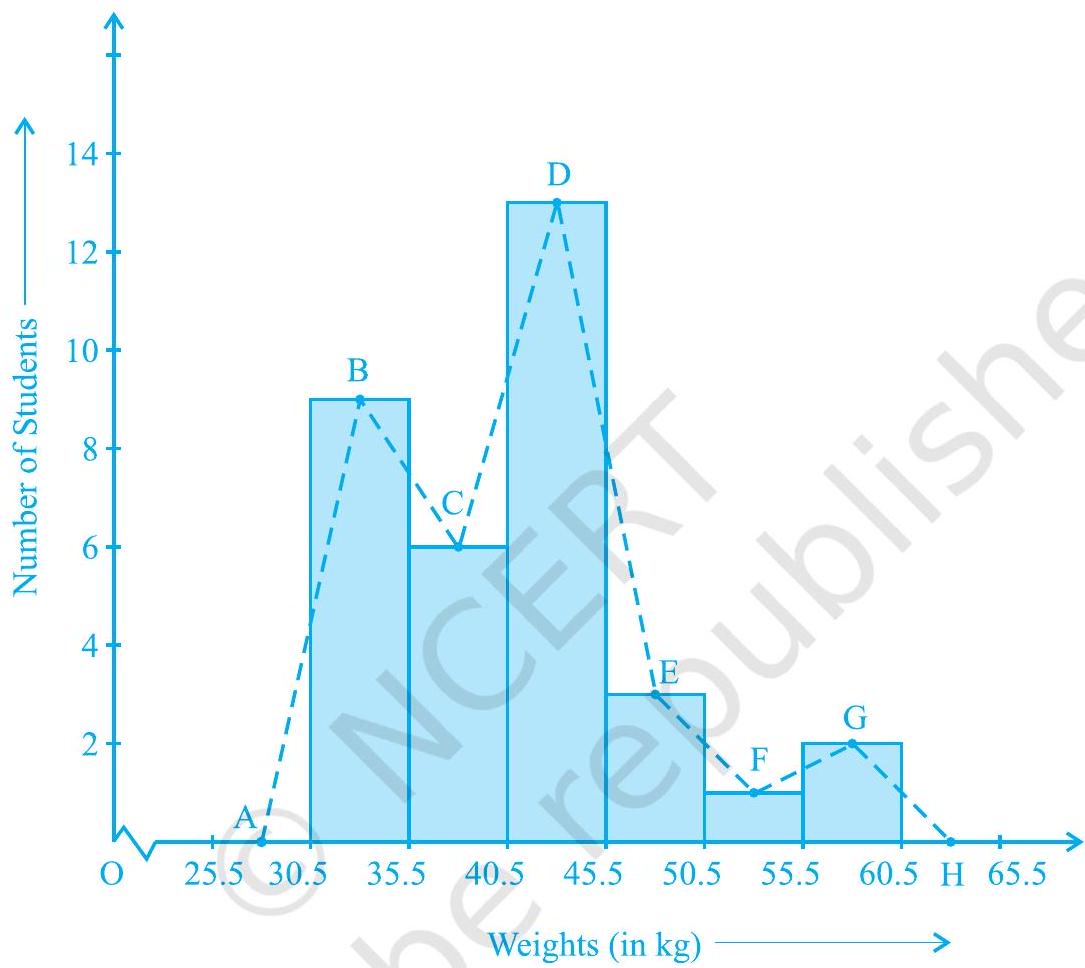
Fig. 12.6
Although, there exists no class preceding the lowest class and no class succeeding the highest class, addition of the two class intervals with zero frequency enables us to make the area of the frequency polygon the same as the area of the histogram. Why is this so? (Hint : Use the properties of congruent triangles.)
Now, the question arises: how do we complete the polygon when there is no class preceding the first class? Let us consider such a situation.
Example 4 : Consider the marks, out of 100, obtained by 51 students of a class in a test, given in Table 12.5.
Table 12.5
| Marks | Number of students |
|---|---|
| 5 | |
| 10 | |
| 4 | |
| 6 | |
| 7 | |
| 3 | |
| 2 | |
| 2 | |
| 3 | |
| 9 | |
| Total | 51 |
Draw a frequency polygon corresponding to this frequency distribution table.
Solution : Let us first draw a histogram for this data and mark the mid-points of the tops of the rectangles as B, C, D, E, F, G, H, I, J, K, respectively. Here, the first class is
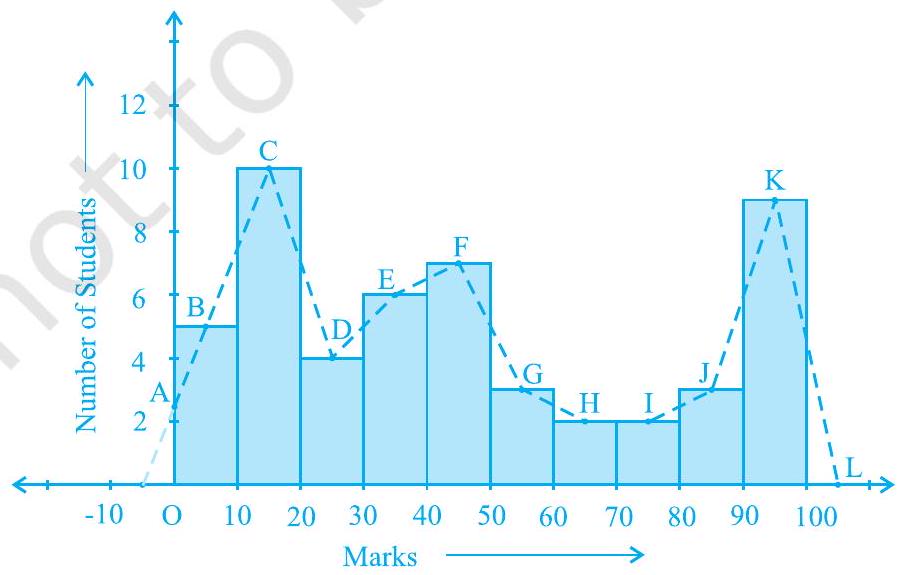
Fig. 12.7
Frequency polygons can also be drawn independently without drawing histograms. For this, we require the mid-points of the class-intervals used in the data. These mid-points of the class-intervals are called class-marks.
To find the class-mark of a class interval, we find the sum of the upper limit and lower limit of a class and divide it by 2 . Thus,
Let us consider an example.
Example 5 : In a city, the weekly observations made in a study on the cost of living index are given in the following table:
Table 12.6
| Cost of living index | Number of weeks |
|---|---|
| 5 | |
| 10 | |
| 20 | |
| 9 | |
| 6 | |
| 2 | |
| Total | 52 |
Draw a frequency polygon for the data above (without constructing a histogram).
Solution : Since we want to draw a frequency polygon without a histogram, let us find the class-marks of the classes given above, that is of
For
So, the class-mark
Continuing in the same manner, we find the class-marks of the other classes as well. So, the new table obtained is as shown in the following table:
Table 12.7
| Classes | Class-marks | Frequency |
|---|---|---|
| 145 | 5 | |
| 155 | 10 | |
| 165 | 20 | |
| 175 | 9 | |
| 185 | 6 | |
| 195 | 2 | |
| Total | 52 |
We can now draw a frequency polygon by plotting the class-marks along the horizontal axis, the frequencies along the vertical-axis, and then plotting and joining the points
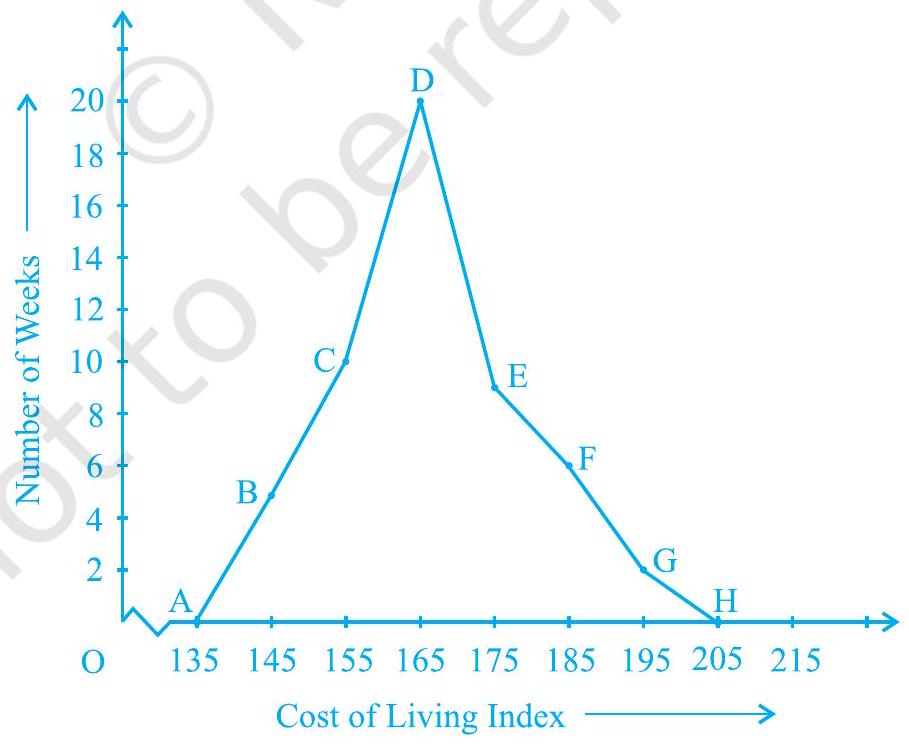
Fig. 12.8
Frequency polygons are used when the data is continuous and very large. It is very useful for comparing two different sets of data of the same nature, for example, comparing the performance of two different sections of the same class.
EXERCISE 12.1
1. A survey conducted by an organisation for the cause of illness and death among the women between the ages 15 - 44 (in years) worldwide, found the following figures (in %):
| S.No. | Causes | Female fatality rate (%) |
|---|---|---|
| 1. | Reproductive health conditions | 31.8 |
| 2. | Neuropsychiatric conditions | 25.4 |
| 3. | Injuries | 12.4 |
| 4. | Cardiovascular conditions | 4.3 |
| 5. | Respiratory conditions | 4.1 |
| 6. | Other causes | 22.0 |
(i) Represent the information given above graphically.
(ii) Which condition is the major cause of women’s ill health and death worldwide?
(iii) Try to find out, with the help of your teacher, any two factors which play a major role in the cause in (ii) above being the major cause.
Show Answer
Solution
(i) The information given in the question is represented below graphically.

Causes
(ii) We can observe from the graph that reproductive health conditions are the major cause of women’s ill health and death worldwide.
(iii) Two factors responsible for the cause in (ii) are
- Lack of proper care and understanding.
- Lack of medical facilities.
2. The following data on the number of girls (to the nearest ten) per thousand boys in different sections of Indian society is given below.
| Section | Number of girls per thousand boys |
|---|---|
| Scheduled Caste (SC) | 940 |
| Scheduled Tribe (ST) | 970 |
| Non SC/ST | 920 |
| Backward districts | 950 |
| Non-backward districts | 920 |
| Rural | 930 |
| Urban | 910 |
(i) Represent the information above by a bar graph.
(ii) In the classroom discuss what conclusions can be arrived at from the graph.
Show Answer
Solution
(i) The information given in the question is represented below graphically.

(ii) From the above graph, we can conclude that the maximum number of girls per thousand boys is present in section ST. We can also observe that the backward districts and rural areas have more girls per thousand boys than nonbackward districts and urban areas.
3. Given below are the seats won by different political parties in the polling outcome of a state assembly elections:
| Political Party | A | B | C | D | E | F |
|---|---|---|---|---|---|---|
| Seats Won | 75 | 55 | 37 | 29 | 10 | 37 |
(i) Draw a bar graph to represent the polling results.
(ii) Which political party won the maximum number of seats?
Show Answer
Solution
(i) The bar graph representing the polling results is given below.

(ii) From the bar graph, it is clear that Party A won the maximum number of seats.
4. The length of 40 leaves of a plant are measured correct to one millimetre, and the obtained data is represented in the following table:
| Length (in mm) | Number of leaves |
|---|---|
| 3 | |
| 5 | |
| 9 | |
| 12 | |
| 5 | |
| 4 | |
| 2 |
(i) Draw a histogram to represent the given data. [Hint: First make the class intervals continuous]
(ii) Is there any other suitable graphical representation for the same data?
(iii) Is it correct to conclude that the maximum number of leaves are
Show Answer
Solution
(i) The data given in the question is represented in the discontinuous class interval. So, we have to make it in the continuous class interval. The difference is 1 , so taking half of 1 , we subtract
| S.No. | Length (in mm) | Number of leaves |
|---|---|---|
| 1. | 3 | |
| 2. | 5 | |
| 3. | 9 | |
| 4. | 12 | |
| 5. | 5 | |
| 6. | 4 | |
| 7. |

(ii) Yes, the data given in the question can also be represented by a frequency polygon.
(iii) No, we cannot conclude that the maximum number of leaves is
5. The following table gives the life times of 400 neon lamps:
| Life time (in hours) | Number of lamps |
|---|---|
| 14 | |
| 56 | |
| 60 | |
| 86 | |
| 74 | |
| 62 | |
| 48 |
(i) Represent the given information with the help of a histogram.
(ii) How many lamps have a life time of more than 700 hours?
Show Answer
Solution
(i) The histogram representation of the given data is given below.

(ii) The number of lamps having a lifetime of more than 700 hours
6. The following table gives the distribution of students of two sections according to the marks obtained by them:
| Section A | Section B | ||
|---|---|---|---|
| Marks | Frequency | Marks | Frequency |
| 3 | 5 | ||
| 9 | 19 | ||
| 17 | 15 | ||
| 12 | 10 | ||
| 9 | 1 |
Represent the marks of the students of both the sections on the same graph by two frequency polygons. From the two polygons compare the performance of the two sections.
Show Answer
Solution
The class-marks
For section A,
| Marks | Class-marks | Frequency |
|---|---|---|
| 5 | 3 | |
| 15 | 9 | |
| 25 | 17 | |
| 35 | 12 | |
| 45 | 9 |
For section B,
| Marks | Class-marks | Frequency |
|---|
| 5 | 5 | |
|---|---|---|
| 15 | 19 | |
| 25 | 15 | |
| 35 | 10 | |
| 45 | 1 |
Representing these data on a graph using two frequency polygon, we get

From the graph, we can conclude that the students of Section A performed better than Section B.
7. The runs scored by two teams A and B on the first 60 balls in a cricket match are given below:
| Number of balls | Team A | Team B |
|---|---|---|
| 2 | 5 | |
| 1 | 6 | |
| 8 | 2 | |
| 9 | 10 | |
| 4 | 5 | |
| 5 | 6 | |
| 6 | 3 | |
| 10 | 4 | |
| 6 | 8 | |
| 2 | 10 |
Represent the data of both the teams on the same graph by frequency polygons.
[Hint : First make the class intervals continuous.]
Show Answer
Solution
The data given in the question is represented in the discontinuous class interval. So, we have to make it in the continuous class interval. The difference is 1 , so taking half of 1 , we subtract
| Number of Balls | Class Mark | Team A | Team B |
|---|---|---|---|
| 3.5 | 2 | 5 | |
| 9.5 | 1 | 6 | |
| 15.5 | 8 | 2 | |
| 9 | 10 |
| 27.5 | 4 | 5 | |
|---|---|---|---|
| 33.5 | 5 | 6 | |
| 39.5 | 6 | 3 | |
| 45.5 | 10 | 4 | |
| 51.5 | 6 | 8 | |
| 57.5 | 2 | 10 |
The data of both teams are represented on the graph below by frequency polygons.

8. A random survey of the number of children of various age groups playing in a park was found as follows:
| Age (in years) | Number of children |
|---|---|
| 5 | |
| 3 | |
| 6 | |
| 12 | |
| 9 | |
| 10 | |
| 4 |
Draw a histogram to represent the data above.
Show Answer
Solution
The width of the class intervals in the given data varies.
We know that,
The area of the rectangle is proportional to the frequencies in the histogram.
Thus, the proportion of children per year can be calculated as given in the table below.
| Age (in years) |
Number of children (frequency) | Width of class | Length of rectangle |
|---|---|---|---|
| 5 | 1 | ||
| 3 | 1 | ||
| 6 | 2 | ||
| 12 | 2 | ||
| 9 | 3 | ||
| 10 | 5 | ||
| 4 | 2 |
Let
y-axis

9. 100 surnames were randomly picked up from a local telephone directory and a frequency distribution of the number of letters in the English alphabet in the surnames was found as follows:
| Number of letters | Number of surnames |
|---|---|
| 6 | |
| 30 | |
| 44 | |
| 16 | |
| 4 |
(i) Draw a histogram to depict the given information.
(ii) Write the class interval in which the maximum number of surnames lie.
Show Answer
Solution
(i) The width of the class intervals in the given data is varying.
We know that,
The area of the rectangle is proportional to the frequencies in the histogram.
Thus, the proportion of the number of surnames per 2 letters interval can be calculated as given in the table below.
| Number of letters | Number of surnames | Width of class | Length of rectangle |
|---|---|---|---|
| 6 | 3 | ||
| 30 | 2 | ||
| 44 | 2 | ||
| 8-12 | 16 | 4 | |
| 4 | 8 |

(ii) 6-8 is the class interval in which the maximum number of surnames lie.
12.2 Summary
In this chapter, you have studied the following points:
1. How data can be presented graphically in the form of bar graphs, histograms and frequency polygons.





